gRPC vs GraphQL with keep-alive
In this blog post I focus on raw performance and try to dispel some myths and misconceptions about where gRPC performance comes from.

This blog post was written in collaboration with Ezrah Ligthart Schenk
For quite some time it seemed as if REST apis with JSON were the only game in town, with other choices falling into legacy or niche projects. This is no longer true in 2018, protocol buffers/gRPC and GraphQL entered the mainstream and are frequently considered for new projects. While there might be great many reasons why one goes for one tech or another, in this blog post I will focus on raw performance and try to dispel some myths and misconceptions about where gRPC performance comes from.
First a small refresher on the two contenders in my little benchmark
GraphQL is a query language for APIs and a runtime for fulfilling those queries. When you send a query to a GraphQL server you will get exactly what you asked for, as opposed to say REST where you get a pre-baked message in its entirety regardless of which field you are interested in. It is also possible to bundle what would constitute multiple calls in REST in a single request, as you can query multiple entities in a single GraphQL query. By default GraphQL sends data as JSON which makes its request latency for basic queries similar to a standard REST api. It does not require any special client in principle, normal HTTP requests lib can be used.
gRPC on the other hand, is somewhat more low-level and requires use of a custom client. It is a remote procedure call system and uses HTTP/2 for transport with all the benefits that it brings like multiplexing. gRPC works with protocol-buffers (protobuf from Google) by default. Protobuf is a language and platform neutral system used to describe data format and is accompanied by a toolset to (de)serialize the data. Because protobuf puts all the data into an efficient binary format, the messages gRPC client and server exchange tend to be much lighter than a JSON equivalent.
These two technologies seem somewhat distant to each other. One is all about flexibility of querying the data and the other about efficiency. It would seem reasonable to assume that gRPC is a good choice for performance critical components of your architecture and GraphQL a better choice for complex quickly evolving APIs where development speed comes at a premium.
Benchmark
People on the internet say gRPC is about 10 times faster than REST-JSON apis, which should largely hold for GraphQL too. But is this the case under all conditions? We decided to test the request speed for gRPC vs GraphQL for ourselves as we are considering GraphQL for some of our inter-server communication. Since we found our results interesting and also somewhat counter-intuitive we decided we would publish them in this blog post. It might help other developers, too!
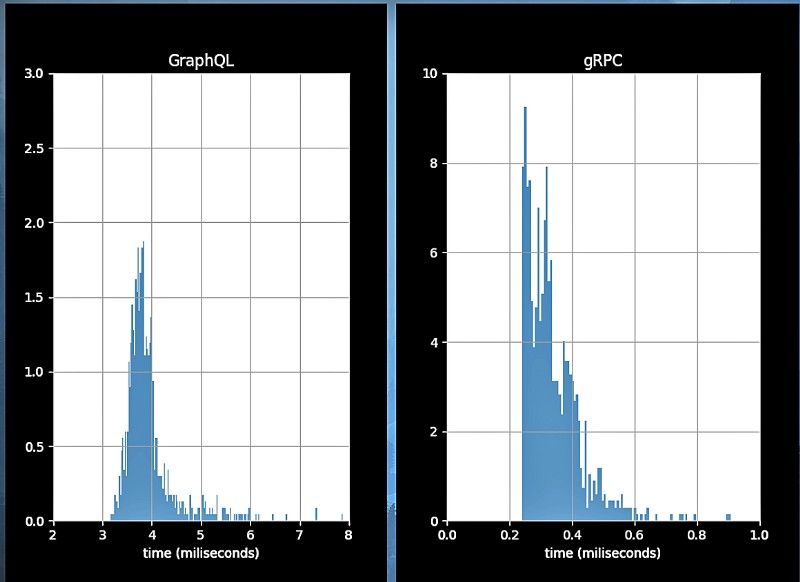
I created a simple Nodejs webapp, one for GraphQL and one for gRPC, and ran it on localhost. I queried the servers 10k times with a script and measured the request latency with different data sizes for each of the apps. I plotted the results using python and matplotlib.
The results are as expected. Like other blog posts state gRPC is about 10 times faster.
I am not happy with the fact that GraphQL is 10X slower. I probably won’t migrate to GraphQL because of that significant difference. Many of you probably assumed that would be the case. Low-level gRPC being faster, and an elegant and high-level solution like GraphQL being slower. Sounds about right, or what one would expect.
But what exactly causes the difference? When comparing messages of the different size we don’t see such a dramatic increase in latency on localhost. That would suggest that (de)serialization is not the biggest factor contributing to the latency. This is also corroborated by another benchmark made by Auth0 where they found that in specific case of Nodejs there isn’t much of a difference in the (de)serialization speed between Protobuf and JSON. This leaves the HTTP part then. What is it that gRPC does differently then?
gRPC uses persistent connections a.k.a keep-alive, this means that once the HTTP connection is opened after the first request made from the gRPC client to the gRPC server it stays open for some time, which can be configured by changing the HTTP headers. And guess what! The time it takes to establish the initial HTTP connection dwarfs the serialization speed.
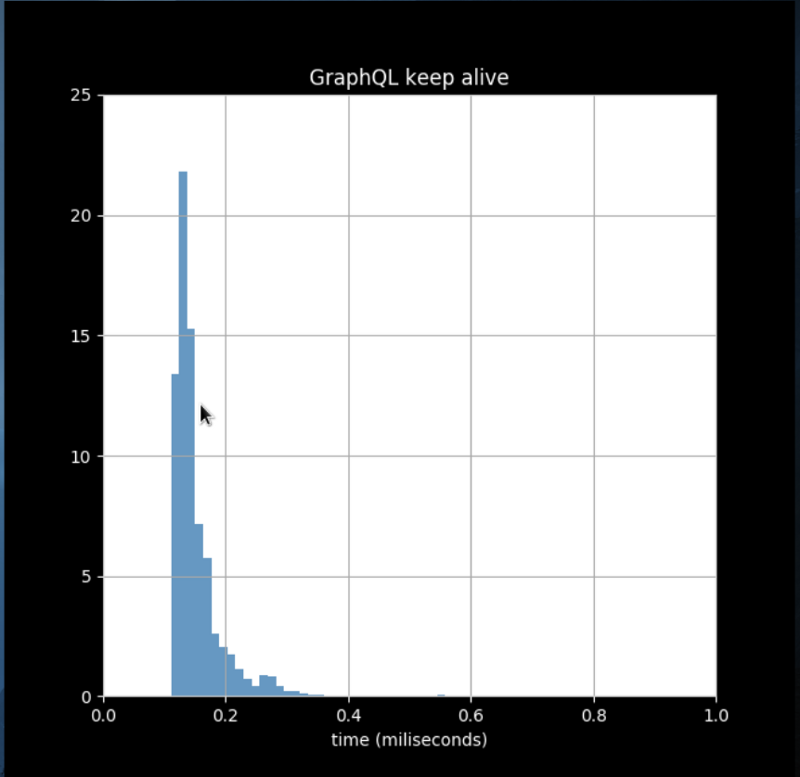
In short: for a Nodejs backend talking to a javascript client, where you can maintain keep-alive connection you gain no performance by going with protobuf/gRPC. For other stacks like Java, the (de)serialization speed becomes a bigger factor, but for small messages you will gain more by making sure the connection is persisted.
If you would like to recreate these results you can try it yourself right here: https://github.com/Q42Philips/protobuf-vs-graphql
Feedback is always welcome!
Check out our Engineering Blog for more in depth stories about pragmatic code for happy users!