Heritage and AI
Putting AI to work: my learnings from projects with Rijksmuseum, RKD – Netherlands Institute for Art History, and The Utrecht Archives


Last month, I had the pleasure of speaking at “The Museum of the Future” conference organised by WUK in the Atomium in Brussels. The topic of my presentation was AI for heritage and archives. This blog post captures the main topics and insights from this presentation. What follows is a tour through several AI heritage projects, the lessons that came out of them, and the questions they leave us with.
I have been working at three intersections of AI and heritage, which form the inspiration for this story. As a project lead at digital studio Q42 (part of Eidra), I work with Rijksmuseum and RKD – Netherlands Institute for Art History. Before that, I spent three years as a program manager at The Utrecht Archives, where we implemented AI solutions for opening up the collection. Alongside that, I run my own company, Aincient, where I work on digital heritage projects, often involving AI.
Searching the Rijksmuseum collection with AI: Natural Language and Visual Search
The first project is the Rijksmuseum Art Explorer. It was launched at the end of 2024 as part of the museum’s new collection online, a couple of months before I joined the team. It was the museum’s first AI-powered search experience, as an addition to the search in the Collection Online. As a user you can answer a question in a chat-like box of the Art Explorer, for example “What do you love?”, in natural language. As a trained Egyptologist, I always test these things with “Ancient Egypt”, and I was delighted to discover a beautiful historic photographic collection with pharaohs and goddesses. Under the hood, Art Explorer uses the open-source CLIP model to facilitate the search.

There’s a lovely touch on top of the search itself: you can curate your own Gallery of Honour from the results. In real life that gallery is reserved for Vermeer and Rembrandt, including the Night Watch. Here you decorate it with whatever you love.
One year later, Visual Search was launched, this time integrated directly into the regular collection search. Users can select an object they like from their regular search in the Collection Online, by clicking on “Search visually”, and the model surfaces other works from the collection that resemble it. For this we use a different open-source model, DINO v3, after having compared models. What we like about DINO is that it does not just match on medium (painting, jewellery, print). It looks at what is depicted. Search on a brooch of a rooster for example, and you get back roosters in completely different materials. That is a much richer way to wander through a collection.
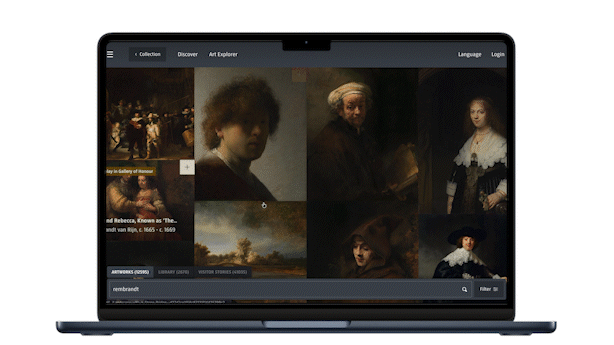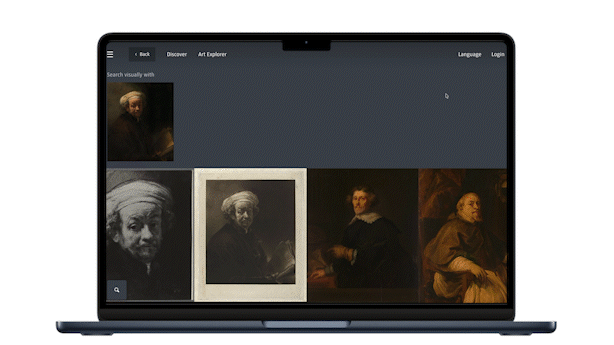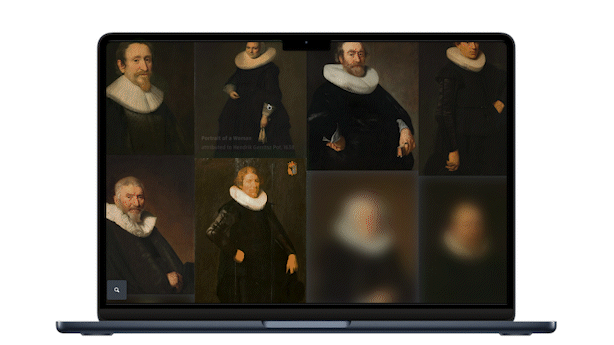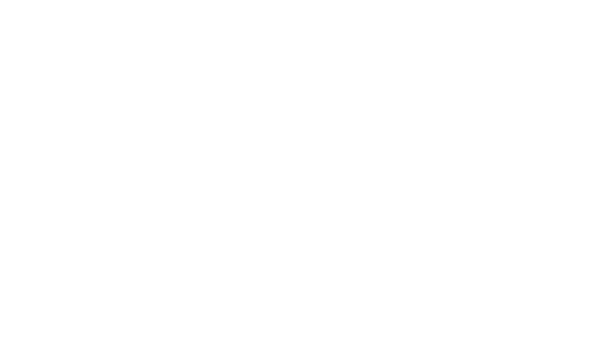
We are now experimenting with the next step: letting users select a segment of an image, recognized by AI. For example a jar in the corner of a still life, and finding that specific object elsewhere in the collection. We have just finished a jumpstart to test the concept, and the results are promising. My colleague Sebastiaan wrote a great engineering blog post on the underlying research that was done a year ago, which is the basis for where we are going next.
Handwritten Text Recognition (HTR) at The Utrecht Archives
Let’s switch perspectives, to my time as program manager at The Utrecht Archives. The collection spans about a thousand years of history, with a lot of difficult-to-read handwriting, for example 17th-century Dutch, and 18th-century French letters. A little over 20% of the collection has been digitised as scans. But a scan alone does not help researchers find what they are looking for, and the handwriting on the scan is not legible for most visitors. Metadata has been created by specialists and volunteers for over many years, but is often incomplete. Transcriptions of parts of the collection were very scarce. We wanted to improve access to the collection by making as many sources full text available as possible, and to add metadata with the help of AI.
The last five years have brought a real revolution in Handwritten Text Recognition (HTR). The specialised platform Transkribus can now handle just about any handwriting at a high level of accuracy. The pipeline works like this: first the layout is identified (where is the text, where are the lines), and then the model produces a transcription. At the time we used the Demeter I model, then state of the art; newer and better models have since arrived.
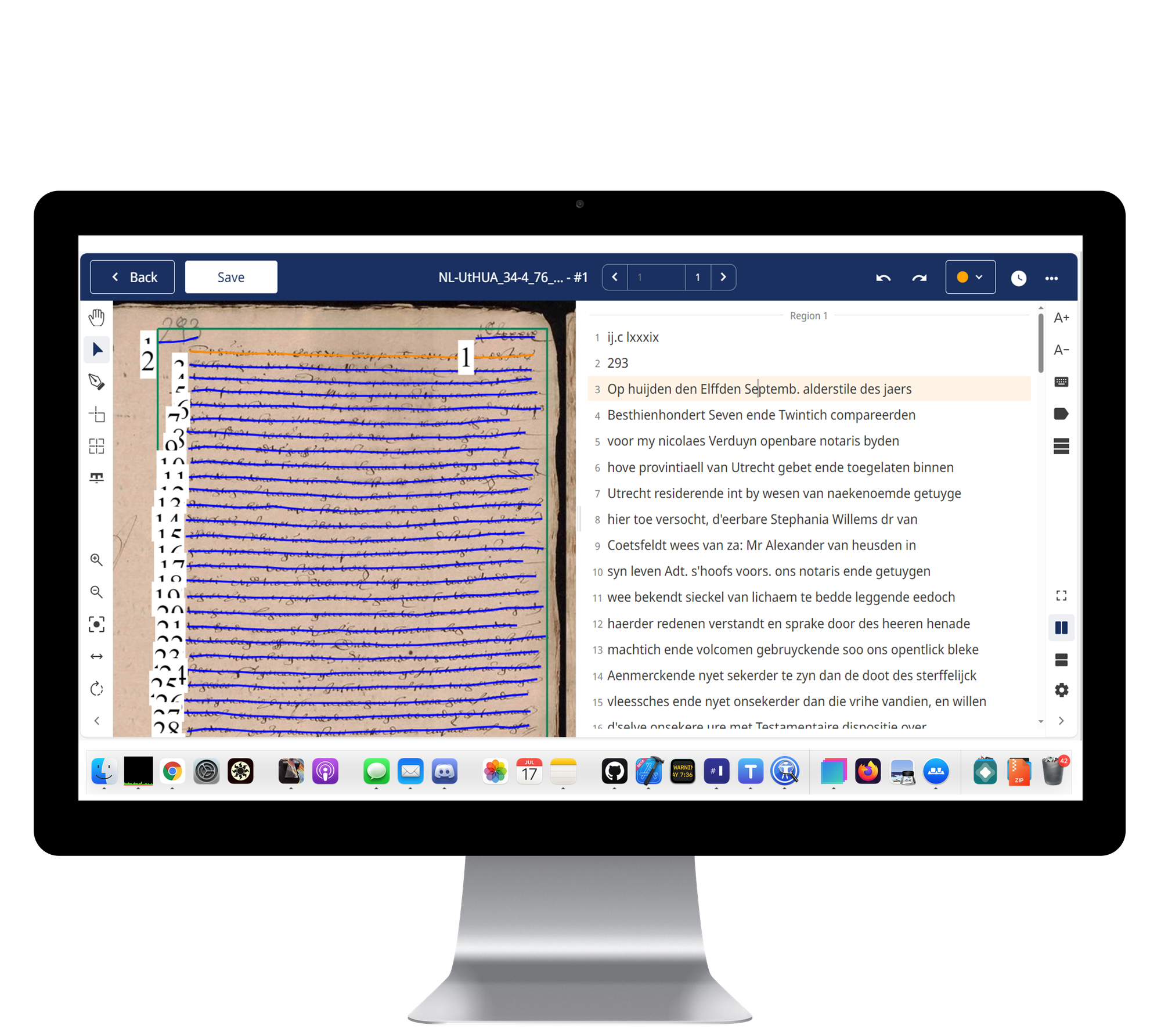
Nowadays, generic models like Gemini are also surprisingly good at this for many use cases, though when I tested one of the OpenAI models a while ago on a difficult text from the 17th century, it started hallucinating. It is likely that also the most difficult handwritings will become an easy task for generic models in the near future.
From transcription to structured metadata - with humans in the loop
Once we had a growing volume of full text, ChatGPT arrived and the obvious next question came up: could we also do information extraction, automating some of the metadata work humans had been doing for many years? We started experimenting under the lead of the wonderful developer working at the archive. From the transcription of a scan, the older GPT models could already produce structured JSON answering the standard questions humans had been annotating for a long time. Such as: when was the text written, what is the text about, who are the main characters and in what role. The results were genuinely exciting, though imperfect: errors creep in at the transcription stage and again at the extraction stage.
We wanted to test in a pilot if we could create a solid AI pipeline and have the outcome checked by volunteers, the so-called humans in the loop. Before starting, we performed a DPIA (Data Protection Impact Assessment) with internal and external experts, which came back positive. The pilot consisted of these steps:
- Transcriptions from scans (HTR) using Transkribus
- Information extraction with GPT-4o
- Human verification by volunteers on the crowdsourcing platform “Het Volk” (The People)
The outcome of the pilot was positive. The pipeline performs well and significantly speeds up metadata creation. Crucially, our volunteers still enjoyed their changed task. We had not taken that for granted since the work shifted from “fill in” to “check and correct”, but the engagement held. The key takeaway is: we have to make sure volunteers stay sharp and focused, because subtle errors can slip through. Without an attentive human eye, these errors are missed. The results are now live on The Utrecht Archives website.
Insights from a one-week archival chatbot sprint
At the end of 2024, we ran a one-week design sprint to prototype a chatbot for the archive, focused on the Amerongen collection. We worked together with multiple experts from several organisations. The goal was both technical - does this work? - and conceptual: what does it do to the accessibility of an archive if you can chat with it?
Two things stood out. First, on the design side: ChatGPT’s interface, all bullets and prose, is quite dull and text heavy. An archive is far richer, it has hierarchy, provenance, visual material, varied sources. A chatbot for an archive ought to feel like that, not like a wall of text. Second, a more uncomfortable question. Users today are conditioned by AI to ask a question and receive an answer. But heritage institutions have always been in the business of offering sources and letting users draw their own conclusions. It is good for heritage institutions to be aware of this and decide what they find most important.
The prototype worked and let users search in a new, exciting way, but it also made some errors such as placing a date in the wrong century. This is the kind of mistake an archive would like to prevent. Still, it is an interesting new way of making collections accessible for a wide audience, which we will probably see more and more in the heritage sector in the coming years.
Sneak preview of a fresh project: AI for genre classification at the RKD
Let’s finish this tour of AI projects with a brand new project on genre classification. The RKD – Netherlands Institute for Art History has a remarkable archive of 19th-century exhibition catalogues listing painters and short descriptions of the works on display. The catalogues are scanned and part of it has been painstakingly annotated by humans for years. RKD would like to use AI to automate that work and came to Q42 for help. They had already been using AI for transcriptions and cleaning of the data, and we had done an AI workshop together on their pipeline. Now they wanted to take a step further: can AI also classify the genre of each work such as portrait, and landscape? The results are positive and more information will follow soon.
Stepping back: opportunities and concerns
After all those examples, it is worth zooming out. The opportunities of AI in heritage are real and concrete, as shown by these examples and the projects of others. Examples are enhanced searchability and more accessible collections, thanks to Visual Search, Handwritten Text Recognition, structured metadata, modernisation and translation, and chatbot-like ways of exploring. It can also help with other internal processes such as improving productivity, and assistance with coding and writing.
The concerns are also real, and they have not shifted much in the last three years: for example bias and ethical concerns, intellectual property violations, hallucinations, no exact reproducibility, climate impact, dependency on big tech, and impact on employment. Each institution has to do its own balancing act. Two things are worth thinking about consciously. Which model are you using, and on which source? At The Utrecht Archives we started with using OpenAI’s GPT models because they were the best tool for the job at that time, but we were also hesitant. We were genuinely excited when the GPT-NL initiative was launched in the Netherlands over two years ago: an initiative aiming for an ethical Dutch AI model. GPT-NL has been winning prizes for this effort, and The Utrecht Archives donated training data to the project. Open-source alternatives exist too - both CLIP and DINO are open source, which is part of why we use them at Q42 for Rijksmuseum.
For a heritage institution it is also important to look at what rights are attached to your published data. If your collection is online, your rights statement matters. Is it public domain? Should it be trainable by others? There are benefits to openness, and downsides if you are trying to push back against extractive use by big tech. The National Library of the Netherlands tightened its terms specifically where it found its data being misused. For more on this, the Impulse paper on publishing cultural heritage data in the age of AI is worth reading.
What I am taking away
Looking back at all of this, a few things stand out for me. AI does offer many opportunities for heritage institutions. Regarding the human aspect, the most successful projects we have worked on were not about replacing humans. They were about changing what humans do. Volunteers at The Utrecht Archives moved from creating metadata to verifying it, and they still found the work meaningful. Curators at the RKD are moving from manual annotation to working with the output of a classifier AI model. The “human in the loop” is where often the quality actually comes from, also in the training process.
Open source models and ethical partners matter. CLIP, DINO, Transkribus, GPT-NL are interesting alternatives for heritage institutions for commercial models of big tech. They let heritage institutions experiment without locking themselves into a single commercial provider.
And the conceptual questions matter as much as the technical ones. The chatbot project taught me that the hardest question was not “can we build it?”. It was “what kind of relationship do we want with our users now that they expect answers, not sources?”.
Using AI for creating this blog post
AI helped me write this blog post. It was not my intention to write a blog post after the conference, but I was asked for one in the comments of a LinkedIn post about my presentation. I liked the idea and decided to see if I could speed up the process with AI. Fortunately, a video of my presentation was available. The transcription was done using Notion AI, since the Claude model (from Anthropic, Opus 4.7) I used did not work with video yet. Based on the transcription and presentation slides, I asked Claude to create a blog post. I tried improving the first version by asking for a bit more formal text, also taking into account some comments of a colleague which I uploaded. It did not improve a lot, so I decided to put myself as a human in the loop and edit the text, which took me a few hours. Although not perfect, it definitely helped speed up the process.
Next stop: Alexandria!
I am very excited to be presenting on AI and Egyptology and hosting an AI workshop at the conference “Ancient Egypt and New Technology 3”, held from the 17th of May till the 20th of May at the Bibliotheca Alexandrina in Egypt. Stay tuned for more information.
Want to dig deeper?
If you want to follow what is happening at the intersection of AI and heritage: here are a few starting points:
- Museumpeil 66 (November 2025, in Dutch): a special issue on AI and museums, oral history and AI, and interviews with experts in the field.
- AI4LAM (LAM stands for libraries, archives and museums) and their annual Fantastic Futures conference. Past presentations are all on YouTube.
- The Q42 blog post by my colleague Sebastiaan Kolmschate on visual search research at Rijksmuseum, which is the foundation for our segmented-search experiments.
- GPT-NL and the “Down to the bottom!” (in Dutch: Tot op de bodem!) KVAN pilot, for what’s happening in the Netherlands specifically.
If you would like to talk about any of this - whether you are a museum, archive or library exploring where to start - I would love to hear from you. You can reach me at heleen.wilbrink@q42.nl.
Heleen Wilbrink is a project lead at Q42 (part of Eidra), where she works with the Rijksmuseum and RKD. She previously spent three years as program manager at The Utrecht Archives, and runs the digital heritage company Aincient.