Zoeken is geen technisch probleem
In deze blogpost leg ik uit, wat we geleerd hebben bij het testen en verbeteren van blackbox-systemen, zoals search en recommendation engines op de Rijksmuseum-website.

Hoe je je resultaten verbetert door je gebruiker beter te begrijpen
Developers houden ervan een complex probleem te pakken, dat te ontleden, en er een elegante oplossing voor te bouwen. Wij dus ook. Bouwen betekent in dit geval dat we een greep doen in onze toolbox van programmeertalen, frameworks, cloud platforms, et cetera en beginnen te programmeren.
Ik durf te stellen dat we die aanpak ondertussen vrij goed beheersen. Maar we komen steeds vaker problemen tegen die we niet kunnen oplossen door er domweg code tegenaan te gooien.
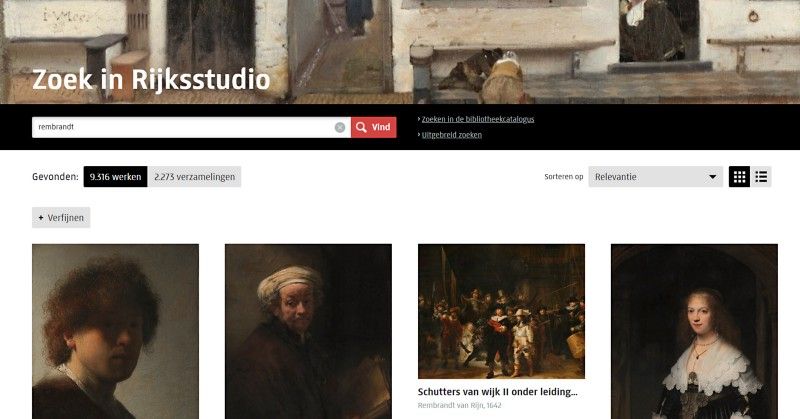
Een voorbeeld daarvan is de zoekfunctionaliteit die we bouwen op websites als rijksmuseum.nl en belowthesurface.amsterdam. Getraind door het jarenlange gebruik van steeds beter wordende zoekmachines, hebben gebruikers bewust of onbewust hele duidelijke verwachtingen van wat er zou moeten gebeuren bij een zoekopdracht. Spelfouten moeten niet uitmaken, de zoekmachine begrijpt synoniemen, en het beste zoekresultaat staat bovenaan.
Het is niet triviaal om dit goed te doen. En als je het wel goed doet, dan is er een goede boterham mee te verdienen. Elastic, voorheen Elasticsearch, is daar een mooi voorbeeld van. Het van oorsprong Nederlandse bedrijf haalde bij beursgang in oktober 2018 een slordige 250 miljoen dollar op.
Grip op search features
Bij Q42 gebruiken we tools als Elastic regelmatig in onze projecten en we zijn ondertussen best bedreven in het configureren — en tweaken — van deze systemen om features te maken die doen wat gebruikers verwachten. Het gebruik van dit soort semi-blackbox systemen heeft echter ook z’n keerzijde. In vergelijking met de code die we zelf schrijven, gedragen zij zich niet 100% voorspelbaar. We kunnen erop vertrouwen dat we een zoekresultaat krijgen als we op rijksmuseum.nl zoeken naar ‘bloemen’, maar waarom Tocht naar Chatham van Arnold Bloem op plaats vijf en niet op plaats vijftien staat, is niet direct te achterhalen.
Hierdoor kan het binnen het scrumproces best lastig zijn om een feature als search te bouwen, zeker in vergelijking met de meer ‘traditionele’ features die we gewend zijn te ontwikkelen. Is de feature af als er een zoekresultaat op de pagina getoond wordt of zijn er nog meer verwachtingen? Welke use cases ondersteunen we en welke niet? Kunnen we expliciet maken wanneer de feature af is, en zo ja, duurt het dan een dag, een paar dagen, een sprint of een paar sprints om dat punt te bereiken?
In de praktijk bepaalt de dynamiek van het project vaak hoeveel tijd we besteden aan een feature als search. In alle gevallen geldt dat de kwaliteit ten minste een gevoelsmatige ondergrens moet behalen. Hoeveel tijd er vervolgens nog aan besteed wordt, loopt erg uiteen. Het gevaar van deze aanpak is dat het een false sense of security schept over hoe onze feature het in praktijk doet. We weten dat we zoekresultaten uit het systeem kunnen krijgen, maar voldoen die ook aan de verwachtingen van onze opdrachtgever, en belangrijker, aan die van eindgebruikers? Bij een normale feature kunnen we expliciet maken welke use cases we supporten en schrijven we geautomatiseerde tests die valideren dat onze feature werkt zoals ontworpen. Zouden we dat ook kunnen doen voor een feature als search?
Zoekgedrag per gebruikersgroep
Om die vraag te kunnen beantwoorden moeten we eerst een stapje terug zetten. Hoewel er hele interessante technische problemen op te lossen zijn in het domein van search, zijn de primaire uitdagingen niet technisch van aard. Mensen verwachten te vinden wat ze zoeken als ze de zoekfunctie op een van onze websites gebruiken. Maar om ze daar in te kunnen bedienen, moeten we die verwachtingen wel kennen.
Laten we het Rijksmuseum weer als voorbeeld nemen. We gaan ervan uit dat gebruikers van de website en de app geïnteresseerd zijn in de collectie van het Rijksmuseum. Zij zoeken bijvoorbeeld naar specifieke objecten als De Nachtwacht. Maar klopt die aanname als we kijken naar het daadwerkelijke zoekgedrag? In praktijk blijkt er inderdaad veel gezocht te worden op topstukken uit de collectie, maar dat is niet het volledige plaatje. Gebruikers zoeken bijvoorbeeld ook op werken als Het meisje met de parel, en de Mona Lisa — werken die in bezit zijn van andere musea. Ook wordt er veel gezocht op onderwerpen met zoektermen als ‘bloemen’, ‘landschap’ en ‘stilleven’. Daar tegenover staan hele specifieke zoekopdrachten op objectnummers als ‘SK-A-2’ — het objectnummer van Portret van een Man van Pieter van Anraedt. Een vierde groep zoektermen wordt gebruikt door mensen die op zoek zijn naar praktische en actuele informatie. Zij zoeken bijvoorbeeld op ‘openingstijden’, ‘rondleiding’, ‘tentoonstelling rembrandt’ en ‘marten en oopjen’.
Uit deze veelheid aan zoektermen wordt duidelijk dat we eigenlijk niet kunnen spreken over dé gebruiker. We hebben te maken met heterogene clusters van gebruikers, elk met hun eigen zoekvraag en verwachtingen over wat ze zullen vinden. Als we die clusters kunnen benoemen en de verwachtingen van die verschillende groepen gebruikers expliciet kunnen maken, helpt ons dat bij het beoordelen van de kwaliteit van onze zoekfunctionaliteit.
In het geval van het Rijksmuseum hebben we waarschijnlijk te maken met ten minste drie groepen gebruikers. De eerste groep bestaat uit eenmalige bezoekers van het museum of de website, zoals toeristen. Zij zoeken op topstukken, bekende kunstenaars en generieke zoektermen als ‘stilleven’ en ‘bloemen’ om een beeld te krijgen van het aanbod het museum. De tweede groep bestaat uit terugkerende bezoekers. Zij kennen het museum beter en hebben specifieke zoekvragen over lopende tentoonstellingen, museumtours of bepaalde onderwerpen als ‘renaissance’ en ‘VOC’. De laatste groep bestaat uit kunstkenners en wetenschappers. Zij zoeken op objectnummers van specifieke werken en op schildertechnieken en -materialen.
Keuzes meetbaar maken
Met deze informatie op zak kunnen we onze search feature gericht gaan optimaliseren. Maar optimaliseren we voor de kunstkenner of de eenmalige bezoeker? Of kunnen we een balans vinden waarmee we elke groep voldoende bedienen? Dit proces dwingt je om als team keuzes te maken over het uiteindelijke softwaredesign van de zoekmachine die je aan het bouwen bent.
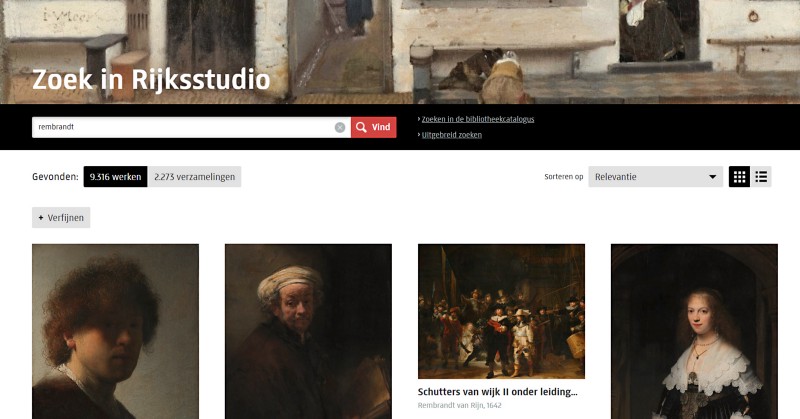
In het uitwerken van deze keuzes is het zaak om ze meetbaar te maken. We kunnen bijvoorbeeld stellen dat de eenmalige gebruikers De Nachtwacht in de eerste vijf zoekresultaten verwachten te vinden als ze zoeken op ‘Rembrandt’. We geven vervolgens bijvoorbeeld vijf punten als het werk op plaats 1 in de zoekresultaten staat, vier punten voor plaats 2, enzovoorts. Dit herhalen we vervolgens voor andere zoekopdrachten voor de groep eenmalige gebruikers, en we doen hetzelfde voor de andere gebruikersgroepen.
Met deze testset is het nu mogelijk om een nulmeting te doen van de kwaliteit van onze zoekmachine. Dit stelt ons in staat om met vertrouwen te gaan experimenteren. Stel dat we De Nachtwacht in de zoekresultaten meer gewicht geven om de zoekresultaten voor eenmalige bezoekers te verbeteren, dan kunnen we nu controleren of dit gevolgen heeft voor andere gebruikersgroepen.
Samen met de testers van Polteq hebben we dit proces in de praktijk uitgeprobeerd. We merkten al snel dat het scoren van je resultaten een behoorlijke klus is en iets wat fijn is om snel te kunnen herhalen na een wijziging. We zagen hier een mooie kans om deze scores geautomatiseerd te berekenen. Onze vrienden bij Polteq zijn druk aan het onderzoeken hoe zo’n tool eruit zou kunnen zien.
Inzicht in zoekkwaliteit
Wat levert deze exercitie ons nou op? De belangrijkste winst zit in de analyse van de gebruikersgroepen en de gezamenlijke discussie die daaruit volgt. Doordat expliciet is gemaakt wat er van de zoekmachine verwacht wordt, heeft de product owner inzicht in de kwaliteit, en kan zij gericht sturen. Scoort de zoekmachine bijvoorbeeld nog te laag voor een belangrijke gebruikersgroep, dan moet een andere feature misschien wachten terwijl de zoekmachine verder geoptimaliseerd wordt. Hoe beter je je gebruikers begrijpt, hoe beter je dat kan doen. Zoeken is geen technisch probleem.
Meer weten over het testen van complexe search- of Machine Learning-modellen om makkelijker aanpassingen te doen? Stuur me een mailtje: jaapm@q42.nl.